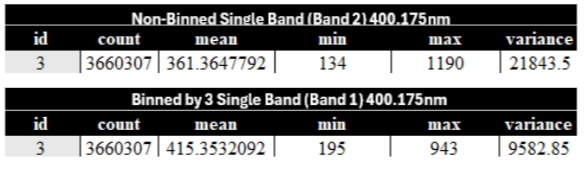
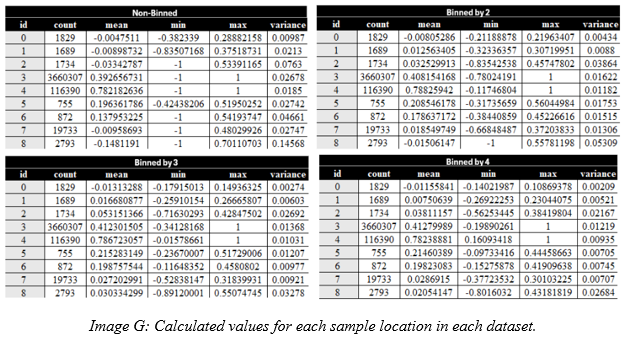
Looking at our initial values we can make some quick observations about the effects of binning. Looking broadly at the values we can see that the minimum value at the sample locations in NB is valued at -1 in six of the locations, with B2 dataset only having a single minimum value of -1. B3 and B4 do not have any minimum values of -1 in the sample areas. On the contrary all of the datasets have max values of 1 in sample locations ID 3 and 4. ID 3 and 4 are vegetative areas and as seen in the count column, have the most pixels to collect values from, so it’s possible this is a bit of an outlier.
Looking closer at ID 0 and 1 we can see the NB dataset has a much lower minimum value than the binned datasets. The variance for ID 0 and 1 is also much higher than the binned datasets. ID 2 sees the mean value and variance of NB and B2 are very different from each other with the mean of the NB dataset being negative, and in B2 it is positive. ID 3 and 4 have very similar mean values to each other, which is evidence in favor that the amount of -1 minimum values we have are a bit of an outlier. Looking at ID 5 and 6 which are two tiny dirt patches, that were selected to try and get pure bare earth. Here we again see a -1 minimum value in NB dataset for ID 6, where in B2 dataset the minimum value is -0.38440859. Again, more evidence that non-binned data has more outlier values. The mean values of ID 5 and 6 are also interestingly very close together, and as the smallest sample locations means the two locations are fairly consistent, though again a slightly larger discrepancy in the NB dataset.
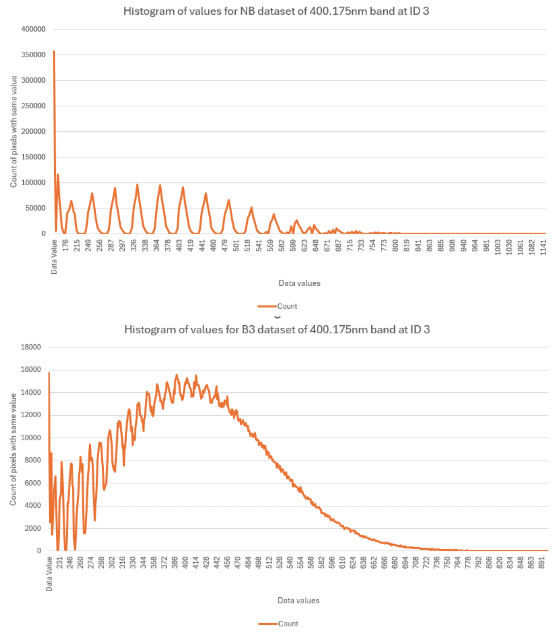
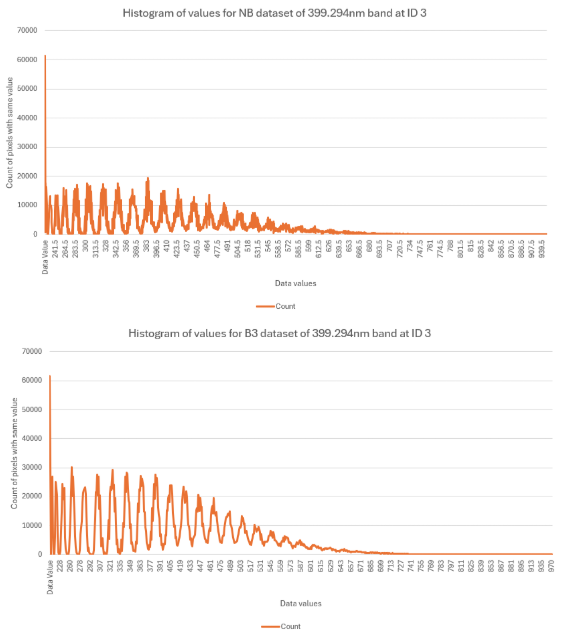
ID 7 and 8 see a large spread of values per dataset. ID 7 and 8 could be assessed as having such large differences due to their man-made nature. However, ID 0, 1, and 2 are also man made, but they are specially designed for consistent reflectivity. There is likely an abundance of noise from the reflected light of these surface because of their material, so each level of binning is correcting for a lot of askew values. Which currently seems to be the takeaway from this NDVI comparison. The NB dataset appears to feature more noise which is corrected heavily for through binning by 2. Subsequent binning can refine values even further, but we must remember that this gets away from the nature of using a hyperspectral camera, compared to something like a multispectral camera.
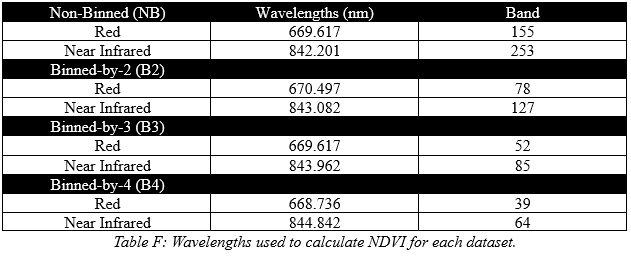
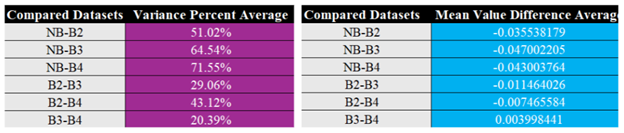
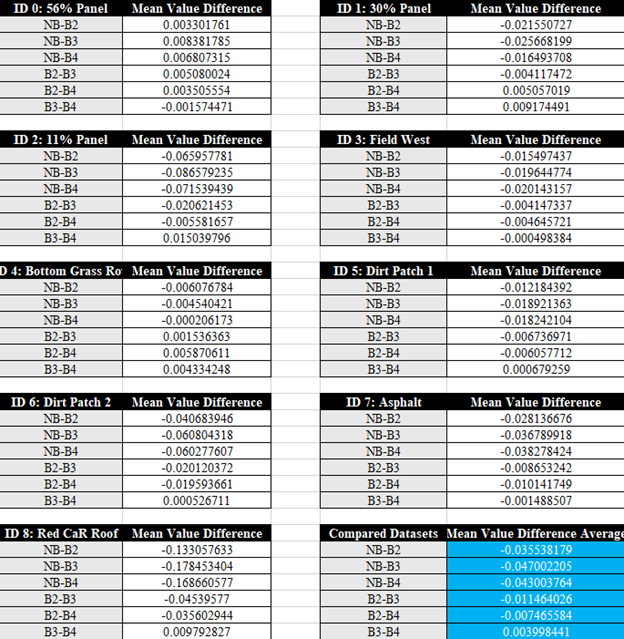
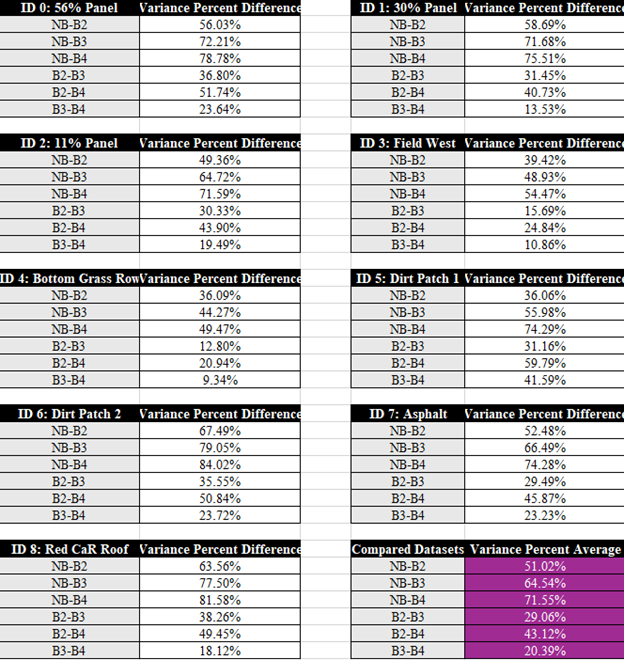
To round out our analysis of these NDVI datasets, below in Image H, Image I, and Image J you will see the average difference of mean values and variance for each dataset at each sample location. Average mean value difference is being shown as actual mean value, and the average variance difference is being shown as a percentage. When it comes to the mean values, we need to remember that NDVI values are on a scale of -1 to 1, which means 0.001 is not a large difference, while 0.01 is equivalent to a 1% percent difference. The average difference between NB and B2 is -0.0355 or about a -3.55% difference in NDVI terms, while the largest difference comes from between NB and B3 at -0.0470 or -4.70%. As an average this is quite a noticeable difference, but as you can take note in Image I ID 8 is an outlier. I do not believe it is fair to remove it from the average as we are not doing this testing for a specific use case but is worth acknowledging.